
On Active Information, search, Islands of Function and FSCO/I
| May 2, 2015 | Posted by kairosfocus under Darwinist rhetorical tactics, Functionally Specified Complex Information & Organization, ID Foundations |
A current rhetorical tack of objections to the design inference has two facets:
(a) suggesting or implying that by moving research focus to Active Information needle in haystack search-challenge linked Specified Complexity has been “dispensed with” [thus,too, related concepts such as FSCO/I]; and
(b) setting out to dismiss Active Information, now considered in isolation.
Both of these rhetorical gambits are in error.
However, just because a rhetorical assertion or strategy is erroneous does not mean that it is unpersuasive; especially for those inclined that way in the first place.
So, there is a necessity for a corrective.
First, let us observe how Marks and Dembski began their 2010 paper, in its abstract:
Needle-in-the-haystack problems look for small targets in large spaces. In such cases, blind search stands no hope of success. Conservation of information dictates any search technique will work, on average, as well as blind search. Success requires an assisted search. But whence the assistance required for a search to be successful? To pose the question this way suggests that successful searches do not emerge spontaneously but need themselves to be discovered via a search. The question then naturally arises whether such a higher-level “search for a search” is any easier than the original search. We prove two results: (1) The Horizontal No Free Lunch Theorem, which shows that average relative performance of searches never exceeds unassisted or blind searches, and (2) The Vertical No Free Lunch Theorem, which shows that the difficulty of searching for a successful search increases exponentially with respect to the minimum allowable active information being sought.
That is, the context of active information and associated search for a good search, is exactly that of finding isolated targets Ti in large configuration spaces W, that then pose a needle in haystack search challenge. Or, as I have represented this so often here at UD:
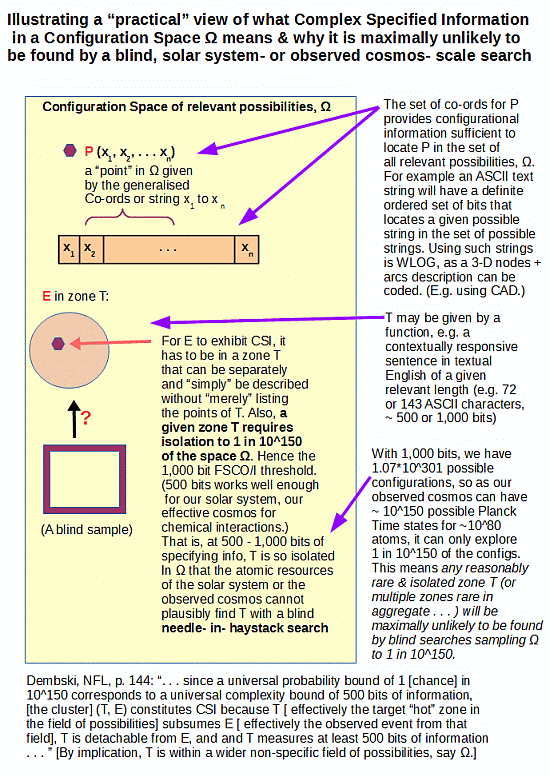 Updating to reflect the bridge to the origin of life challenge:
Updating to reflect the bridge to the origin of life challenge:
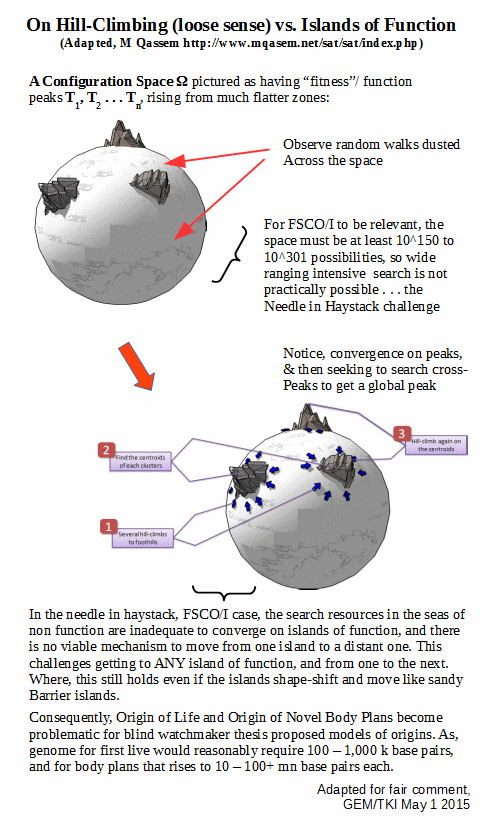
In this model, we see how researchers on evolutionary computing typically confine their work to tractable cases where a dust of random walk searches with drift due to a presumably gentle slope on what looks like a fairly flat surface is indeed likely to converge on multiple zones of sharply rising function, which then allows identification of likely local peaks of function. The researcher in view then has a second tier search across peaks to achieve a global maximum.
This of course contrasts with the FSCO/I [= functionally specific, complex organisation and/or associated information] case where
a: due to a need for multiple well-matched parts that
b: must be correctly arranged and coupled together
c: per a functionally specific wiring diagram
d: to attain the particular interactions that achieve function, and so
e: will be tied to an information-rich wiring diagram that
f: may be described and quantified informationally by using
g: a structured list of y/n q’s forming a descriptive bit string
. . . we naturally see instead isolated zones of function Ti amidst a much larger sea of non-functional clustered or scattered arrangements of parts.
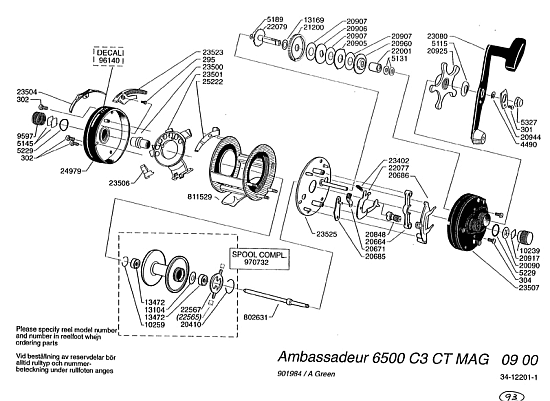
This may be illustrated by an Abu 6500 C3 fishing reel exploded view assembly diagram:
. . . which may be compared to the organisation of a petroleum refinery:
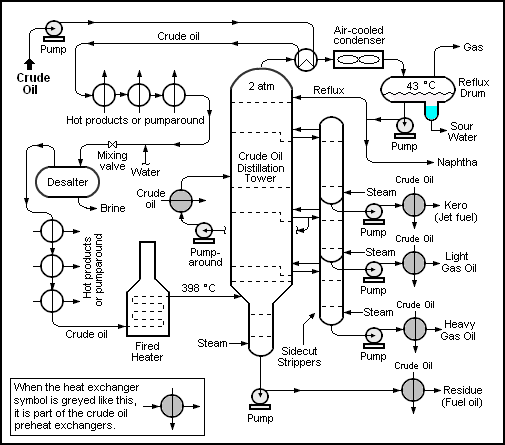
Petroleum refinery block diagram illustrating FSCO/I in a process-flow system
. . . and to that of the cellular protein synthesis system:
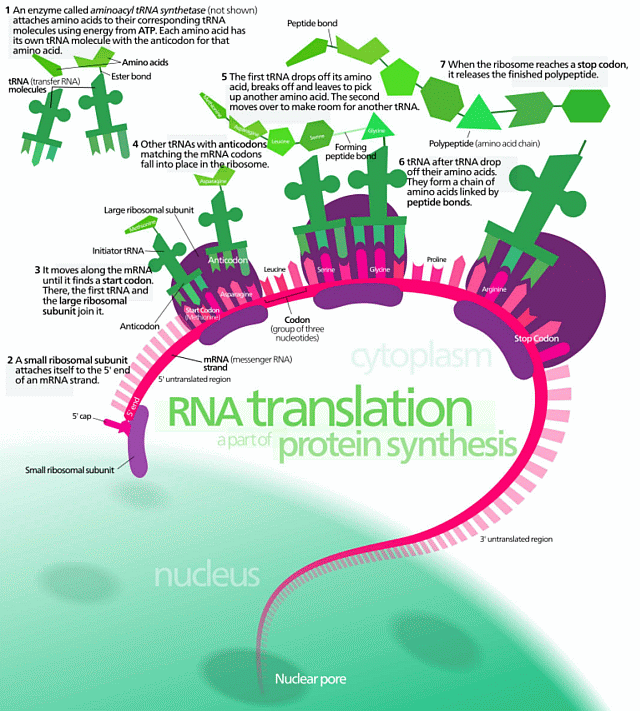
Protein Synthesis (HT: Wiki Media)
. . . and onward the cellular metabolic process network (with the above being the small corner top left):
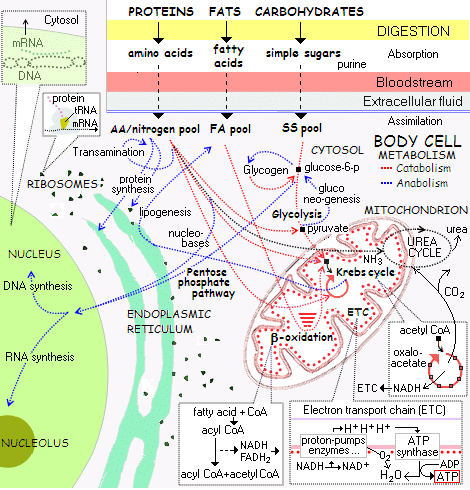
(NB: I insist on presenting this cluster of illustrations to demonstrate to all but the willfully obtuse, that FSCO/I is real, unavoidably familiar and pivotally relevant to origin of cell based life discussions, with implications onward for body plans that must unfold from an embryo or the like, OOL and OOBP.)
Now, in their 2013 paper on generalising their analysis, Marks, Dembski and Ewert begin:
All but the most trivial searches are needle-in-the-haystack problems. Yet many searches successfully locate needles in haystacks. How is this possible? A success-ful search locates a target in a manageable number of steps. According to conserva-tion of information, nontrivial searches can be successful only by drawing on existing external information, outputting no more information than was inputted [1]. In previous work, we made assumptions that limited the generality of conservation of information, such as assuming that the baseline against which search perfor-mance is evaluated must be a uniform probability distribution or that any query of the search space yields full knowledge of whether the candidate queried is inside or outside the target. In this paper, we remove such constraints and show that | conservation of information holds quite generally. We continue to assume that tar-gets are fixed. Search for fuzzy and moveable targets will be the topic of future research by the Evolutionary Informatics Lab.
In generalizing conservation of information, we first generalize what we mean by targeted search. The first three sections of this paper therefore develop a general approach to targeted search. The upshot of this approach is that any search may be represented as a probability distribution on the space being searched. Readers who are prepared to accept that searches may be represented in this way can skip to section 4 and regard the first three sections as stage-setting. Nonetheless, we sug-gest that readers study these first three sections, if only to appreciate the full gen-erality of the approach to search we are proposing and also to understand why attempts to circumvent conservation of information via certain types of searches fail. Indeed, as we shall see, such attempts to bypass conservation of information look to searches that fall under the general approach outlined here; moreover, conservation of information, as formalized here, applies to all these cases . . .
So, again, the direct relevance of FSCO/I and linked needle in haystack search challenge continues.
Going further, we may now focus:
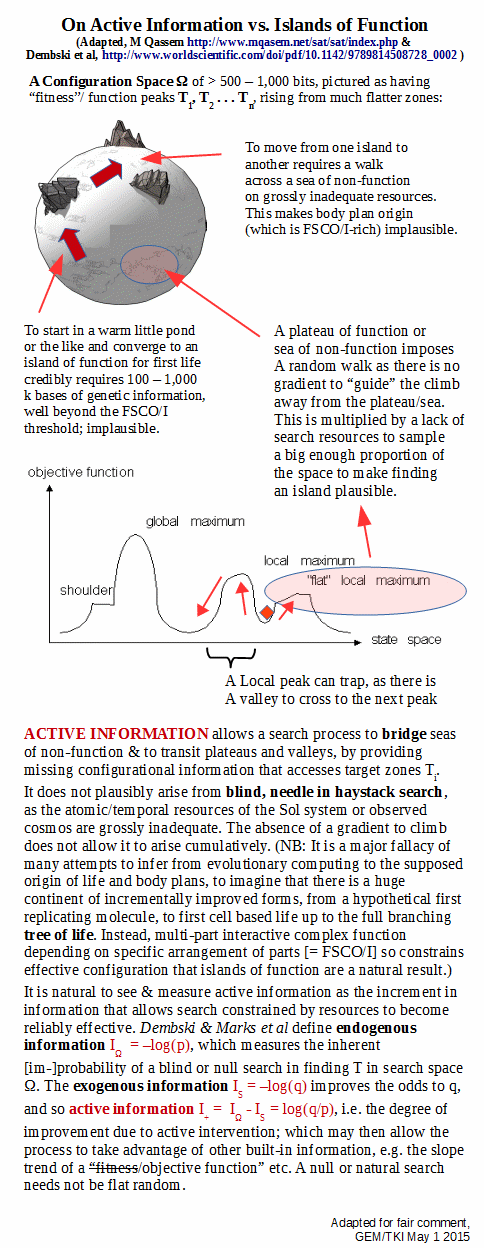
In short, active information is a bridge that allows us to pass to relevant zones of FSCO/I, Ti, and to cross plateaus and intervening valleys in an island of function that does not exhibit a neatly behaved objective function. And, it is reasonable to measure it’s impact based on search improvement, in informational terms. (Where, it may only need to give a hint, try here and scratch around a bit: warmer/colder/hot-hot-hot. AI itself does not have to give the sort of detailed wiring diagram description associated with FSCO/I.)
It must be deeply understood, that the dominant aspect of the situation is resource sparseness confronting a blind needle in haystack search. A reasonably random blind search will not credibly outperform the overwhelmingly likely failure of the yardstick, flat random search. Too much stack, too few search resources, too little time. And a drastically improved search, a golden search if you will, itself has to be found before it becomes relevant.
That means, searching for a good search.
Where, a search on a configuration space W, is a sample of its subsets. That is, it is a member of the power set of W, which has cardinality 2^W. Thus it is plausible that such a search will be much harder than a direct fairly random search. (And yes, one may elaborate an analysis to address that point, but it is going to come back to much the same conclusion.)
Further, consider the case where the pictured zones are like sandy barrier islands, shape-shifting and able to move. That is, they are dynamic.
This will not affect the dominant challenge, which is to get to an initial Ti for OOL then onwards to get to further islands Tj etc for OOBP. That is doubtless a work in progress over at the Evolutionary Informatics Lab, but is already patent from the challenge in the main.
To give an outline idea, let me clip a summary of the needle-to-stack challenge:
Our observed cosmos has in it some 10^80 atoms, and a good atomic-level clock-tick is a fast chem rxn rate of perhaps 10^-14 s. 13.7 bn y ~10^17 s. The number of atom-scale events in that span in the observed cosmos is thus of order 10^111.
The number of configs for 1,000 coins (or, bits) is 2^1,000 ~ 1.07*10^301.
That is, if we were to give each atom of the observed cosmos a tray of 1,000 coins, and toss and observe then process 10^14 times per second, the resources of the observed cosmos would sample up to 1 in 10^190 of the set of possibilities.
It is reasonable to deem such a blind search, whether contiguous or a dust, as far too sparse to have any reasonable likelihood of finding any reasonably isolated “needles” in the haystack of possibilities. A rough calc suggests that the ratio is comparable to a single straw drawn from a cubical haystack ~ 2 * 10^45 LY across. (Our observed cosmos may be ~ 10^11 LY across, i.e. the imaginary haystack would swallow up our observed cosmos.)
Of course, as posts in this thread amply demonstrate the “miracle” of intelligently directed configuration allows us to routinely produce cases of functionally specific complex organisation and/or associated information well beyond such a threshold. For an ASCII text string 1,000 bits is about 143 characters, the length of a Twitter post.
As just genomes for OOL start out at 100 – 1,000 k bases and those for OOBP credibly run like 10 – 100+ mn bases, this is a toy illustration of the true magnitude of the problem.
The context and challenge addressed by the active information concept is blind needle in haystack search challenge, and so also FSCO/I. The only actually observed adequate cause of FSCO/I is intelligently directed configuration, aka design. And per further experience, design works by injecting active information coming from a self-moved agent cause capable of rational contemplation and creative synthesis.
So, FSCO/I remains as best explained on design. In fact, per a trillion member base of observations, it is a reliable sign of it. Which has very direct implications for our thought on OOL and OOBP.
Or, it should. END






26 Responses to On Active Information, search, Islands of Function and FSCO/I
Leave a Reply
You must be logged in to post a comment.




On Active Information, search, Islands of Function and FSCO/I
kairosfocus: Conservation of information …
No such theorem. You probably mean Wolpert & Macready’s No Free Lunch Theorem.
kairosfocus: … any search technique will work, on average, as well as blind search.
However, biological evolution is a specific ‘search algorithm’, not the universal set of search algorithms; and the natural environment is a specific ‘fitness landscape’, not the universal set of fitness landscapes.
kairosfocus: {snip all that follows from faulty premises}
What part of “any” don’t you understand?
.
Z:
1: I do not “mean” anything, I am explicitly (and cf the onward linked papers of some dozens of pp altogether) citing Marks, Dembski et al who do have an extensive discussion of conservation of info in search-like phenomena, including several theorems. So, no, conservation of information theorems and associated proofs exist, first restricted cases then more general ones, with yet more in prospect.
2: before we get to OOBP and discuss biological evolution, we have to first get to biology, i.e. OOL.
3: This means that we have to find an empirically grounded means of getting to the FSCO/I in cell based life including that of its embedded von Neumann code using kinematic self replication facility. Where, the only empirically warranted source of bridging active information is intelligently directed configuration, aka design.
4: Having got to first cell based life with the only empirically warranted serious candidate on the table being design, that puts the next issue, that design sits at the table as of right in explaining OOBP.
5: Where, it then emerges that such OOBP must be an account of origin of even more FSCO/I than for OOL dozens of times over, which then is under the same point, that FSCO/I is credibly a reliable signature of design as cause.
6: In addition, the hoped for all-powerful chance variation plus differential reproductive success subtracting less successful varieties leading to incremental descent with modification extrapolated across the tree of life icon, is in the relevant sense a search mechanism, with chance variation creating novel varieties and with differential success subtracting the less successful.
7: This mechanism is known to work somewhat within islands of function, e.g. finch beak lengths, and the variations of red deer that move from North American Elk to the deer of Europe . . . which were found to interbreed in the forests of New Zealand. And of course the different finches of the Galapagos are found to interbreed too.
8: Varieties of dogs show that artificial selection can create similar variations.
9: However, given the FSCO/I challenge, leading to the need to cross gaps between islands, which are of order 10 – 100+mn bases as a first estimate, OOBP by this mechanism is not credible.
10: Further to this, there is no good evidence of a vast continent of incrementally improved varieties from microbes to Mozart, mice, molluscs and mango trees. Not in a fossil record of sudden appearance and disappearance, stasis of form and gaps in morphology. Not in the molecular structures, especially protein families and AA sequence space gaps (a capital case of islands of function), not in the Cambrian Revolution, not in bio-geography, not in industrial melanism, not in homology, not in real embryology, and so forth. Yes, it is demanded ideologically by a priori evolutionary materialism and it is imposed via the iconic tree of life, but the evidence for it, of incremental and cumulative broad, branching variation that starts with closely linked populations then diverges step by step is just not there.
11: On the contrary the evidence just of deeply isolated protein fold domains in AA sequence space and the abundance of very small domains that often appear distinctively among taxonomically close species, itself points to a strong case of islands of function.
12: So, once we move away from an initial island, we do face the issue of crossing a sea of non-functional forms to achieve another island of function, and this will make the very same Darwinist mechanism very likely indeed to meet the same challenge that it is unlikely to find the needles in the haystack given available atomic resources and time.
_____________
Nope, Darwinist chance variation and differential reproductive success leading to culling out of less successful varieties, is not a credible free lunch, golden search.
Unsurprising, as the engines of variation it appeals to boil down to chance processes uncorrelated with future possible success, it can only reward so to speak immediate incremental success embedded in a population. (Notice, so-called natural selection, is an information SUBTRACTION process, culling out less successful varieties.)
As in, your hoped for snip, find a point to dismiss, then sweep away all else, fails.
KF
Cantor, thanks for watching my 6. Indeed, we may ask, what part of “any” and what part of the need for OOBP to cross intervening arms of the ocean of non-functional forms on a small planet of is it 10^43 atoms within available time, is it that is not understood. But, for ideological reasons, there is a common perception that “natural selection” answers to all problems once we get to an initial self replicating entity. It seems to be very hard for the adherents to see that hey are facing serious issues with that broad brush extrapolation from minor adaptation to OOBP. And the bigger problem yet of accounting for OOL involving gated metabolic automata using sophisticated nanotech machinery, and embedding a code using von Neumann self replication facility is even more a-begging. But then it’s what, coming on three years we have had no comers to seriously answer to the UD essay challenge to provide an adequately warranted basis for the ToL from the root up. KF
kairosfocus:
The information for a software replicator is not very improbable.
That is something I intend to pursue in parallel with an ID model.
I think that ID has bigger problems than improbability to deal with.
For instance, what kind of body plan should I design to fit into a current environment without knowing what that environment will be like 200 years in the future?
Information about the future is necessary in order for ID to work.
Zachriel: First off, OOL precedes the existence of biological evolution, which starts when the first self replicator with heritable random variation comes into existence. So your entire point is moot regarding OOL.
Second, what makes you think biological evolution is such a great search? It suffers from a lot of limitations. The most critical limitation is that each step in the search process must be “functional”, i.e. a living organism. The second limitation is that the random variation source is extremely poor quality — most mutations are neutral or harmful, and mutations are rare making the search process slow. Third, the selection function (what reproduces or not) is poor — it can only operate as a binary function on an entire organism, and can’t apply fine tuning to a specific feature at a time. Also there is a ton of randomness involved — for example 98% of tadpoles die before becoming adult frogs, and it’s mostly blind luck. What if one of those that died had a beneficial mutation?
Those are just limitations specific to biological evolution. Evolutionary algorithms in general have additional challenges. There is a lot of fine tuning required to make one work. If selection is too strong, an algorithm gets stuck on local maxima, whereas if it’s too weak, it takes too long or drifts away from fitness peaks. If the mutation rate is too low, novelty requiring coordinated mutations can never arise, and if it’s too high, you get too many deleterious mutations fixed, leading to error catastrophe. Even with perfect tuning, it’s possible for fitness landscapes to exist that are impossible to traverse given finite resources.
So far, the argument of evolutionists is question begging: because life exists, we know the search algorithm and fitness landscape are masterfully fine tuned to produce complex life. They have never demonstrated this fact though, and all experimental attempts to do so have failed. Their materialist philosophy requires them to believe this on faith.
I will now predict your response: you will say that my description of evolution “leaves out some details”, and those magic golden details fix all the problems I listed (for example, to one of my previous comments, you threw out the buzzword “recombination” — I could pick that apart if you want). Or changing fitness landscapes, or deep time, or drift, or whatever. No evidence will be given to mathematically support the position that those details matter. Before you mention a detail, consider how much it really helps.
The problem is that adding lots of details makes it impossible to rigorously model something. That’s what evolutionists hide behind: ID researchers haven’t modeled evolution completely — well neither have evolutionists! At least ID researchers try to make forward progress on the math (such as studying Active Information), whereas evolutionists are happy with their just so stories.
NRG:
Second, what makes you think biological evolution is such a great search? It suffers from a lot of limitations. The most critical limitation is that each step in the search process must be “functional”, i.e. a living organism. The second limitation is that the random variation source is extremely poor quality — most mutations are neutral or harmful, and mutations are rare making the search process slow. Third, the selection function (what reproduces or not) is poor — it can only operate as a binary function on an entire organism, and can’t apply fine tuning to a specific feature at a time. Also there is a ton of randomness involved — for example 98% of tadpoles die before becoming adult frogs, and it’s mostly blind luck. What if one of those that died had a beneficial mutation?
It makes you wonder what kind of designer creates such an inefficient design.
KF:
A question, part 21200 seems to be a gear of some kind, if one loses a tooth does the FSCO/i decrease? if so does the broken tooth have the missing Fsco?
The gear might be functional with the loss of one tooth but say we lose 10, and the part is no longer functional as per the design, would that be any ,part or total loss of FSco ? Thanks
Just curious
cantor: What part of “any” don’t you understand?
What part of “on average” don’t you understand. The term refers to the universe of possible search algorithms and the universe of possible fitness landscapes. However, specific search algorithms may do better on specific fitness landscapes. The question, then, isn’t mathematical, but empirical.
kairosfocus: So, no, conservation of information theorems and associated proofs exist, first restricted cases then more general ones, with yet more in prospect.
They only have validity as restatements of No Free Lunch theorems. Notably, you called it “conservation of information”, but made a statement from the No Free Lunch theorem.
NetResearchGuy: First off, OOL precedes the existence of biological evolution, which starts when the first self replicator with heritable random variation comes into existence.
The original post is discussing “evolutionary computing”.
NetResearchGuy: Second, what makes you think biological evolution is such a great search? It suffers from a lot of limitations.
Quite so! The vast majority of structures will be forever outside the reach of evolutionary search.
NetResearchGuy: If selection is too strong, an algorithm gets stuck on local maxima, whereas if it’s too weak, it takes too long or drifts away from fitness peaks.
Recombination resolves most of the problems associated with being stuck on local maxima.
NetResearchGuy: They have never demonstrated this fact though, and all experimental attempts to do so have failed.
There is substantial scientific evidence supporting evolution. You might start with the historical record.
Zachriel
If “evolution” is the creation by unguided processes from a common ancestor of all the different kinds of living beings ever existed, its evidence is exactly zero.
The historical record, being a collection of static findings, cannot prove such evolution (= dynamic) by definition.
Huh? I thought GAs were used in a lot of horrible cases when, for example, the fitness function wasn’t (a) tractable (in which case by definition we can use methods which find the maximum), and (b) are multi-modal, so occasional large-scale changes are needed to find the maximum. Multi-modal problems are usually pretty intractable.
I see Winston Ewert has commented about KF’s FSCO/I idea:
and upthread:
So there you have it, KF. Get publishing!
If unguided evolution is any clue then publishing is meaningless.
For me, the most fundamental piece of evidence that is missing to support evolution is the scarcity of phenotypic vestigial features in extant organisms. (Evolutionists will claim the genome contains vestigial junk in the form of duplicate or non coding DNA, which is debatable, but let’s ignore that).
For example, the just so story for eye evolution suggests that some specialized refractive cells happened to spontaneously appear at the front of the eye to become a cornea. How did the cells know where to appear in the body? Why didn’t they appear in the animal’s mouth or spleen or elsewhere?
In order for evolution to function, it must have tried a ton of failed experiments placing refractive cells in random places all over the body, before it finally had that success. So if we were to look at living organisms, we should see bizarre cases in biology of animals with parts in random places that do nothing useful. It should be the rule, rather an exception. I know there are mutations that cause extra wings or legs or toes, but those are just the same genes triggered extra times, not novel vestigial features. And those are never selectively beneficial.
Regarding the historical record, I want to see a fossil with half a wing. Show me that.
niwrad: The historical record, being a collection of static findings, cannot prove such evolution (= dynamic) by definition.
A temporal sequence can certainly support a scientific hypothesis when the sequence is entailed in that hypothesis.
NetResearchGuy: or example, the just so story for eye evolution suggests that some specialized refractive cells happened to spontaneously appear at the front of the eye to become a cornea.
Refraction is actually a complex process, so it wouldn’t appear randomly, but only after a number of other potentiating changes. The basic process is thought to be an eyepatch, then invagination, then a transparent membrane to protect the organ, then this creates a situation which is conducive to further specialization and refraction. Each of these steps is incremental and selectively advantageous, meaning it constitutes a plausible pathway. There are examples of each of these intermediate forms in nature.
NetResearchGuy: Regarding the historical record, I want to see a fossil with half a wing.
There are many intermediate wings in nature.
http://iliketowastemytime.com/.....irrel1.jpg
AS,
isn’t it interesting how you neatly omitted the context in which I highlighted how Orgel and Wicken went on record since the 1970;s as well as Dembski in NFL pp 148 – 9 and Meyer in his response to Falk, from here on:
http://www.uncommondescent.com.....ent-562213
Do you see why you force me to conclude that you are playing a snip out of context and snipe, strawman caricature game?
Besides, you are here plainly refusing to attend to something so blatantly obvious in front of you that it is at the level of A is A.
Namely, that there is a relevant subset of specific, complex information in the biological and technological etc worlds, where the specification is functional. That is, per a wiring diagram configuration, parts put together in a certain cluster of ways will work to do a job that emerges from their interaction. This is shown in the OP above in several ways — and don’t overlook the text strings that because of how they are put together constitute a message in English.
Let me clip Dembski from NFL, to help rivet the point, as he is discussing something that should not even be remarkable, just a description of patent facts — the debate should be on where functionally specific complex organisation and/or associated information [FSCO/I] as a relevant subset of the more general CSI comes from, not whether it exists. That, is patent, it is undeniably all around us, it is in the text of this comment and yours too, in the PCs we are using, and in our bodies beginning with DNA code and organisation of the living cell.
So, Dembski:
Meyer, backs this up:
All I have done is to add complexity to emphasise that there is a threshold — typically, 500 – 1,000 bits will be more than enough — of complexity to get the phrase, functionally specific complex information, FSCI. As GP often emphasises, when this is openly digitally coded FSCI, we may abbreviate dFSCI. And to take in cases where wiring diagram organisation may imply rather than openly express the information [per, a structured string of Y/N Q's that describe and specify the functional wiring diagram, cf. OP above], we have functionally specific complex organisation and/or associated information, FSCO/I.
There is no need to go to a further publication in the professional literature to establish the meaning and reasonableness of the term.
That, should be trivial.
That it is not, is a sign that it has such strong basis that by any rhetorical means deemed necessary it is to be excluded, dismissed, expelled, locked out and mocked with schoolyard taunt tactics.
That, is shameful.
KF
PS, someone above asked what will happen to the FSCO/I in a reel that has a damaged gear. With a wholly or partially missing tooth, it might work though not as well — still within the island of function — this sometimes happens with automobile transmissions. If it is bent and will jam the gearing, it might cause functionality to cease. In either case, the issue of FSCO/I beyond a threshold being a reliable marker of design remains.
.
Bob O’H: With a lot of fine tuning, GAs and kin work within islands of function. With the addition of a higher tier they may search out a global optimum, as the cited case gives. But when the dominating sea of non function is material, it takes bridging active information to get them to do the job. And that is intelligently provided. KF
Carpathian:
The hardware and background software to get a software replicator to work is quite complex beyond 128 bytes worth of info, thank you.
Unsurprisingly, it is designed.
But, we are not interested in cellular automata and toy virtual worlds. That is why I have repeatedly pointed to a von Neumann, code using KINEMATIC self replicator. Whether with nanotech or a so-called clanking replicator, that is what is needed.
And, that is no mean feat, we can conceptualise but a system such as a universal computer or the like that embeds an integrated vNSR is by no means trivial. And as I have pointed to, it is what would trigger Industrial Revolution 3.) and open the gateway to solar system colonisation.
That is also what in effect Paley put on the table over 200 years ago when he amplified on just what sort of watch he was pondering in his thought exercise, in Ch 2 of Nat Theol:
That is where we need to begin considerations.
And I find it highly material to note that I have never seen a dismissal of Paley’s watch discussion that seriously engages with what is implied by this.
KF
Zachriel
Also if, for hypothesis, we concede that transformations occurred no evolutionist can prove that such transformations were the result of *unguided* evolution (instead of intelligent design frontloading).
niwrad: Also if, for hypothesis, we concede that transformations occurred no evolutionist can prove that such transformations were the result of *unguided* evolution (instead of intelligent design frontloading).
Baby steps. So you now agree that historical evidence can support a scientific hypothesis? Say, the hypothesis that dinosaurs once roamed the Earth?
Niw, & Z:
A serious survey of the molecular situation and the gross morphology will come up with an absence of actual demonstration of the gradualistic incrementalism of the dominant neo-darwinian school of thought.
That is a demonstrable fact that led to the rise of a whole alternate school of thought, punctuated equilibria.
And, I simply point to Meyer’s runaway continued bestseller, Darwin’s Doubt, for book length documentation despite the usual attempted brushoffs.
The fact is, the issues on the Cambrian fossil revolution were on the table in Darwin’s day and he hoped future finds would fill in gaps. 150 years later, 250,000+ fossil species, millions in museums, billions in the ground and the pattern of gaps is still there.
The dominant pattern is NOT gradualism from unicellular organisms across the branching tree of life. And with so large a sample in hand, if such gradualism were dominant, it should have long since been seen.
The island of function issue is abundantly manifest with proteins in AA space on up to gross body plans.
Which is what the logic tells us to expect.
If you dispute this simply provide the dominant evidence of this gradualism.
And we have not touched the biggest gap of all: OOL.
KF
Z, that there were animals that we now call dinosaurs (and which would have been termed dragons at other times and places) that have gone extinct is neither a scientific hypothesis nor a seriously disputed fact. What would be a relevant hyp with good grounding would be molecular and gross morphology observations documenting in detail their gradual arrival. That, you do not have, so please do not take something else and use it in a way that suggests what you do not have. KF
PS: A gliding squirrel is nowhere near addressing the transformations to create a bat or a bird.
Indeed. They must be carefully designed.
Mung, as must essentially be all software and the hardware for them to run on. Ponder what is really going on in a Java Hello World. Or even an HTML one. KF
Only because the information is front-loaded into the landscape (or the search).
You haven’t solved the problem of the origin of that information.
All you’ve done is push the problem to another domain.